This chapter provides functions for solving various mathematical optimization problems by solvers based on local stopping criteria. The main classes of problems covered in this chapter are:
Linear Programming (LP)
– dense and sparse;
Quadratic Programming (QP)
– convex and nonconvex, dense and sparse;
Quadratically Constrained Quadratic Programming (QCQP)
– convex and nonconvex;
Nonlinear Programming (NLP)
– dense and sparse, based on active-set SQP methods or
interior point methods (IPM)
;
Second-order Cone Programming (SOCP)
;
Semidefinite Programming (SDP)
– both
linear matrix inequalities (LMI)
and
bilinear matrix inequalities (BMI)
;
Derivative-free Optimization (DFO)
;
Least Squares (LSQ)
, data fitting – linear and nonlinear, constrained and unconstrained.
For a full overview of the functionality offered in this chapter, see Section 6 or the Chapter Contents (Chapter E04).
See also other chapters in the Library relevant to optimization:
Chapter E05 contains functions to solve global optimization problems;
Chapter H addresses problems arising in operational research and focuses on
Mixed Integer Programming (MIP)
;
Chapters F07 and F08 include functions for linear algebra and in particular unconstrained linear least squares;
Chapter E02 focuses on curve and surface fitting, in which linear data fitting in or norm might be of interest;
Chapter G02 offers several regression (data fitting) functions, including linear, nonlinear and quantile regression, LARS, LASSO and others.
This introduction is only a brief guide to the subject of optimization. It discusses a classification of the optimization problems and presents an overview of the algorithms and their stopping criteria to help with the choice of a correct solver for a particular problem. Anyone with a difficult or protracted problem to solve will find it beneficial to consult a more detailed text, see Gill et al. (1981), Fletcher (1987) or Nocedal and Wright (2006). If you are unfamiliar with the mathematics of the subject you may find Sections 2.1, 2.2, 2.3, 2.6 and 4 a useful starting point.
2Background to the Problems
2.1Introduction to Mathematical Optimization
Mathematical Optimization, also known as Mathematical Programming, refers to the problem of finding values of the inputs from a given set so that a function (called the objective function) is minimized or maximized. The inputs are called decision variables, primal variables or just variables. The given set from which the decision variables are selected is referred to as a feasible set and might be defined as a domain where constraints expressed as functions of the decision variables hold certain values. Each point of the feasible set is called a feasible point.
A general mathematical formulation of such a problem might be written as
where denotes the decision variables, the objective function and the feasibility set. In this chapter we assume that . Since maximization of the objective function is equivalent to minimizing , only minimization is considered further in the text. Some functions allow you to specify whether you are solving a minimization or maximization problem, carrying out the required transformation of the objective function in the latter case.
A point is said to be a local minimum of a function if it is feasible () and if for all near . A point is a global minimum if it is a local minimum and for all feasible . The solvers in this chapter are based on algorithms which seek only a local minimum, however, many problems (such as convex optimization problems) have only one local minimum. This is also the global minimum. In such cases the Chapter E04 solvers find the global minimum. See Chapter E05 for solvers which try to find a global solution even for nonconvex functions.
2.2Classification of Optimization Problems
There is no single efficient solver for all optimization problems. Therefore, it is important to choose a solver which matches the problem and any specific needs as closely as possible. A more generic solver might be applied, however the performance suffers in some cases, depending on the underlying algorithm.
There are various criteria to help to classify optimization problems into particular categories. The main criteria are as follows:
Type of objective function;
Type of constraints;
Size of the problem;
Smoothness of the data and available derivative information.
Each of the criteria is discussed below to give the necessary information to identify the class of the optimization problem. Section 2.5 presents the basic properties of the algorithms and Section 4 advises on the choice of particular functions in the chapter.
2.2.1Types of objective functions
In general, if there is a structure in the problem the solver should benefit from it. For example, a solver for problems with the sum of squares objective should work better than when this objective is treated as a general nonlinear objective. Therefore, it is important to recognize typical types of the objective functions.
An optimization problem which has no objective is equivalent to having a constant objective, i.e., . It is usually called a feasible point problem. The task is to then find any point which satisfies the constraints.
A linear objective function is a function which is linear in all variables and, therefore, can be represented as
where . Scalar has no influence on the choice of decision variables and is usually omitted. It will not be used further in this text.
A quadratic objective function is an extension of a linear function with quadratic terms as follows:
Here is a real symmetric matrix. In addition, if is positive semidefinite (all its eigenvalues are non-negative), the objective is convex. In convex case the quadratic term might also be defined in a factorized form as follows:
where can be viewed as a factor of . For instance, the objective function in a linear least squares problem falls into this class as its quadratic term is and .
A general nonlinear objective function is any without a special structure.
Special consideration is given to the objective function in the form of a sum of squares of functions, such as
where ; often called residual functions. This form of the objective plays a key role in data fitting solved as a least squares problem as shown in Section 2.2.3.
2.2.2Types of constraints
Not all optimization problems have to have constraints. If there are no restrictions on the choice of except that , the problem is called unconstrained and thus every point is a feasible point.
Simple bounds on decision variables (also known as box constraints or bound constraints) restrict the value of the variables, e.g., . They might be written in a general form as
or in the vector notation as
where and are -dimensional vectors. Note that lower and upper bounds are specified for all the variables. By conceptually allowing and or full generality in various types of constraints is allowed, such as unconstrained variables, one-sided inequalities, ranges or equalities (fixing the variable).
The same format of bounds is adopted to linear and nonlinear constraints in the whole chapter. Note that for the purpose of passing infinite bounds to the functions, all values above a certain threshold (typically ) are treated as .
Linear constraints are defined as constraint functions that are linear in all of their variables, e.g., . They can be stated in a matrix form as
where is a general rectangular matrix and and are -dimensional vectors. Each row of represents linear coefficients of one linear constraint. The same rules for bounds apply as in the simple bounds case.
Although the bounds on could be included in the definition of linear constraints, we recommend you distinguish between them for reasons of computational efficiency as most of the solvers treat simple bounds explicitly.
Quadratic constraints are defined as quadratic functions of a set of variables in a standard form as
where is a symmetric matrix, is an -dimensional vector and is a scalar. If is positive semidefinite, the constraint is convex. In convex case a quadratic constraint may also be defined in its factorized form, similarly to the quadratic objective function, as
where is a rectangular matrix which can be viewed as a factor of .
A set of nonlinear constraints may be defined in terms of a nonlinear function and the bounds and which follow the same format as simple bounds and linear constraints:
Although the linear constraints could be included in the definition of nonlinear constraints, again we prefer to distinguish between them for reasons of computational efficiency.
There are two commonly used second-order cones (also known as quadratic, Lorentz or ice cream cones): a quadratic cone and a rotated quadratic cone. They are defined by the following inequalities:
•Quadratic cone:
(1)
•Rotated quadratic cone:
(2)
Here denotes a subset of the decision variables . Such cones do not necessarily appear naturally in the model formulations so a reformulation is often needed. For example, all convex quadratic constraints or many types of norm minimization problems can be written as quadratic cones, see Section 9.1 in e04ptc.
A matrix constraint (or matrix inequality) is a constraint on eigenvalues of a matrix operator. More precisely, let denote the space of real symmetric matrices and let be a matrix operator , i.e., it assigns a symmetric matrix for each . The matrix constraint can be expressed as
where the inequality for is meant in the eigenvalue sense, namely all eigenvalues of the matrix should be non-negative (the matrix should be positive semidefinite).
There are two types of matrix constraints allowed in the current mark of the Library. The first is linear matrix inequality (LMI) formulated as
and the second one, bilinear matrix inequality (BMI), stated as
Here all matrices , are given real symmetric matrices of the same dimension. Note that the latter type is in fact quadratic in , nevertheless, it is referred to as bilinear for historical reasons.
2.2.3Typical classes of optimization problems
Specific combinations of the types of the objective functions and constraints give rise to various classes of optimization problems. The common ones are presented below. It is always advisable to consider the closest formulation which covers your problem when choosing the solver. For more information see classical texts such as Dantzig (1963), Gill et al. (1981), Fletcher (1987), Nocedal and Wright (2006) or Chvátal (1983).
A
Linear Programming (LP)
problem is a problem with a linear objective function, linear constraints and simple bounds. It can be written as follows:
Quadratic Programming (QP)
problems optimize a quadratic objective function over a set given by linear constraints and simple bounds. Depending on the convexity of the objective function, we can distinguish between convex and nonconvex (or general) QP.
Quadratically Constrained Quadratic Programming (QCQP)
problems extend quadratic programming problems with a set of quadratic constraints. Depending on the convexity of the objective function and quadratic constraints, we can distinguish between convex and nonconvex (or general) QCQP.
Nonlinear Programming (NLP)
problems allow a general nonlinear objective function and any of the nonlinear, quadratic, linear or bound constraints. Special cases, when some (or all) of the constraints are missing, are termed as unconstrained, bound-constrained or linearly-constrained nonlinear programming and might have a specific solver as some algorithms take special provision for each of the constraint type. Problems with a linear or quadratic objective and nonlinear constraints should still be solved as general NLPs.
Second-order Cone Programming (SOCP)
problems are composed of a linear objective function, linear constraints, simple bounds and one or more quadratic cones. The SOCP problem may be written as
where is a Cartesian product of quadratic or rotated quadratic cones (as defined in Section 2.2.2) and -dimensional real space. Note that the cones in a formulation may overlap (i.e., one decision variable may be involved in more than one quadratic cone). SOCP is a very powerful model for many convex problems, however, typically it is necessary to reformulate the model to obtain the form above. Convex QCQP problems are reformulated automatically by the solver, for others see Section 9.1 in e04ptc, Alizadeh and Goldfarb (2003) and Lobo et al. (1998).
Semidefinite Programming (SDP)
typically refers to linear semidefinite programming thus a problem with a linear objective function, linear constraints and linear matrix inequalities:
This problem can be extended with a quadratic objective and bilinear (in fact quadratic) matrix inequalities. We refer to it as a semidefinite programming problem with bilinear matrix inequalities (BMI-SDP):
A
Least Squares (LSQ)
problem is a problem where the objective function in the form of sum of squares is minimized subject to usual constraints. If the residual functions are linear or nonlinear, the problem is known as linear or nonlinear least squares, respectively. Not all types of the constraints need to be present which brings up special cases of unconstrained, bound-constrained or linearly-constrained least squares problems as in NLP .
This form of the problem is very common in data fitting as demonstrated on the following example. Let us consider a process that is observed at times and measured with results , for . Furthermore, the process is assumed to behave according to a model where are parameters of the model. Given the fact that the measurements might be inaccurate and the process might not exactly follow the model, it is beneficial to find model parameters so that the error of the fit of the model to the measurements is minimized. This can be formulated as an optimization problem in which are decision variables and the objective function is the sum of squared errors of the fit at each individual measurement, thus:
2.2.4Problem size, dense and sparse problems
The size of the optimization problem plays an important role in the choice of the solver. The size is usually understood to be the number of variables and the number (and the type) of the constraints. Depending on the size of the problem we talk about small-scale, medium-scale or large-scale problems.
It is often more practical to look at the data and its structure rather than just the size of the problem. Typically, in a large-scale problem not all variables interact with everything else. It is natural that only a small portion of the constraints (if any) involves all variables and the majority of the constraints depends only on small different subsets of the variables. This creates many explicit zeros in the data representation which it is beneficial to capture and pass to the solver. In such a case the problem is referred to as sparse. The data representation usually has the form of a sparse matrix which defines the linear constraint matrix , Jacobian matrix of the nonlinear constraints or the Hessian of the objective . Common sparse matrix formats are used, such as coordinate storage (CS) and compressed column storage (CCS) (see Section 2.1 in the F11 Chapter Introduction).
The counterpart to a sparse problem is a dense problem in which the matrices are stored in general full format and no structure is assumed or exploited. Whereas passing a dense problem to a sparse solver presents typically only a small overhead, calling a dense solver on a large-scale sparse problem is ill-advised; it leads to a significant performance degradation and memory overuse.
2.2.5Derivative information, smoothness, noise and
Derivative-free Optimization (DFO)
Most of the classical optimization algorithms rely heavily on derivative information. It plays a key role in necessary and sufficient conditions (see Section 2.4) and in the computation of the search direction at each iteration (see Section 2.5). Therefore, it is important that accurate derivatives of the nonlinear objective and nonlinear constraints are provided whenever possible.
Unless stated otherwise, it is assumed that the nonlinear functions are sufficiently smooth. The solvers will usually solve optimization problems even if there are isolated discontinuities away from the solution, however you should always consider whether an alternative smooth representation of the problem exists. A typical example is an absolute value which does not have a first derivative for . Nevertheless, if the model allows it can be transformed as
which avoids the discontinuity of the first derivative. If many discontinuities are present, alternative methods need to be applied such as e04cbc or stochastic algorithms in Chapter E05, e05sacore05sbc.
The vector of first partial derivatives of a function is called the gradient vector, i.e.,
the matrix of second partial derivatives is termed the Hessian matrix, i.e.,
and the matrix of first partial derivatives of the vector-valued function is known as the Jacobian matrix:
If the function is smooth and the derivative is unavailable, it is possible to approximate it by finite differences, a change in function values in response to small perturbations of the variables. Many functions in the Library estimate missing elements of the gradients automatically this way. The choice of the size of the perturbations strongly affects the quality of the approximation. Too small perturbations might spoil the approximation due to the cancellation errors in floating-point arithmetic and too big reduce the match of the finite differences and the derivative (see e04xac for optimal balance of the factors). In addition, finite differences are very sensitive to the accuracy of . They might be unreliable or fail completely if the function evaluation is inaccurate or noisy such as when is a result of a stochastic simulation or an approximate solution of a PDE.
Derivative-free Optimization (DFO)
represents an alternative to derivative-based optimization algorithms. DFO solvers neither rely on derivative information nor approximate it by finite differences. They sample function evaluations across the domain to determine a new iteration point (for example, by a quadratic model through the sampled points). They are, therefore, less exposed to the relative error of the noise of the function because the sample points are never too close to each other to take the error into account. DFO might be useful even if the finite differences can be computed as the number of function evaluations is lower. This is particularly beneficial for problems where the evaluations of are expensive. DFO solvers tend to exhibit a faster initial progress to the solution, however, they typically cannot achieve high-accurate solutions.
2.2.6Minimization subject to bounds on the objective function
In all of the above problem categories it is assumed that
where and . Problems in which and/or are finite can be solved by adding an extra constraint of the appropriate type (i.e., linear or nonlinear) depending on the form of . Further advice is given in Section 4.7.
2.2.7Multi-objective optimization
Sometimes a problem may have two or more objective functions which are to be optimized at the same time. Such problems are called multi-objective, multi-criteria or multi-attribute optimization. If the constraints are linear and the objectives are all linear then the terminology goal programming is also used.
Although there is no function dealing with this type of problems explicitly in this mark of the Library, techniques used in this chapter and in Chapter E05 may be employed to address such problems, see Section 2.5.5.
2.3Geometric Representation
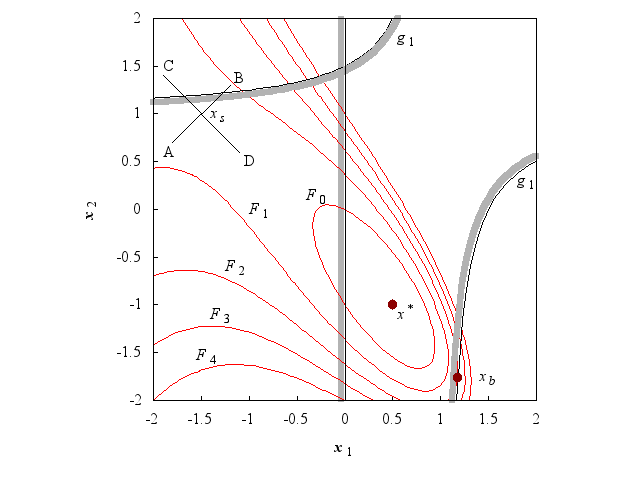
To illustrate the nature of optimization problems it is useful to consider the following example:
(This function is used as the example function in the documentation for the unconstrained functions.)
Figure 1
Figure 1 is a contour diagram of . The contours labelled are isovalue contours, or lines along which the function takes specific constant values. The point is a local unconstrained minimum, that is, the value of () is less than at all the neighbouring points. A function may have several such minima. The point is said to be a saddle point because it is a minimum along the line AB, but a maximum along CD.
If we add the constraint (a simple bound) to the problem of minimizing , the solution remains unaltered. In Figure 1 this constraint is represented by the straight line passing through , and the shading on the line indicates the unacceptable region (i.e., ).
If we add the nonlinear constraint , represented by the curved shaded line in Figure 1, then is not a feasible point because . The solution of the new constrained problem is , the feasible point with the smallest function value (where ).
2.4Sufficient Conditions for a Solution
All nonlinear functions will be assumed to have continuous second derivatives in the neighbourhood of the solution.
2.4.1Unconstrained minimization
The following conditions are sufficient for the point to be an unconstrained local minimum of :
(i) and
(ii) is positive definite,
where denotes the Euclidean norm.
2.4.2Minimization subject to bounds on the variables
At the solution of a bounds-constrained problem, variables which are not on their bounds are termed free variables. If it is known in advance which variables are on their bounds at the solution, the problem can be solved as an unconstrained problem in just the free variables; thus, the sufficient conditions for a solution are similar to those for the unconstrained case, applied only to the free variables.
Sufficient conditions for a feasible point to be the solution of a bounds-constrained problem are as follows:
(i); and
(ii) is positive definite; and
(iii); ,
where is the gradient of with respect to the free variables, and is the Hessian matrix of with respect to the free variables. The extra condition (iii) ensures that cannot be reduced by moving off one or more of the bounds.
2.4.3Linearly-constrained minimization
For the sake of simplicity, the following description does not include a specific treatment of bounds or range constraints, since the results for general linear inequality constraints can be applied directly to these cases.
At a solution , of a linearly-constrained problem, the constraints which hold as equalities are called the active or binding constraints. Assume that there are active constraints at the solution , and let denote the matrix whose columns are the columns of corresponding to the active constraints, with the vector similarly obtained from ; then
The matrix is defined as an matrix satisfying:
The columns of form an orthogonal basis for the set of vectors orthogonal to the columns of .
Define
, the projected gradient vector of ;
, the projected Hessian matrix of .
At the solution of a linearly-constrained problem, the projected gradient vector must be zero, which implies that the gradient vector can be written as a linear combination of the columns of , i.e., . The scalar is defined as the Lagrange multiplier corresponding to the th active constraint. A simple interpretation of the th Lagrange multiplier is that it gives the gradient of along the th active constraint normal; a convenient definition of the Lagrange multiplier vector (although not a recommended method for computation) is:
Sufficient conditions for to be the solution of a linearly-constrained problem are:
(i) is feasible, and ; and
(ii), or equivalently, ; and
(iii) is positive definite; and
(iv) if corresponds to a constraint ;
if corresponds to a constraint .
The sign of is immaterial for equality constraints, which by definition are always active.
2.4.4Nonlinearly-constrained minimization
For nonlinearly-constrained problems, much of the terminology is defined exactly as in the linearly-constrained case. To simplify the notation, let us assume that all nonlinear constraints are in the form . The set of active constraints at again means the set of constraints that hold as equalities at , with corresponding definitions of and : the vector contains the active constraint functions, and the columns of are the gradient vectors of the active constraints. As before, is defined in terms of as a matrix such that:
where the dependence on has been suppressed for compactness.
The projected gradient vector is the vector . At the solution of a nonlinearly-constrained problem, the projected gradient must be zero, which implies the existence of Lagrange multipliers corresponding to the active constraints, i.e., .
The Lagrangian function is given by:
We define as the gradient of the Lagrangian function; as its Hessian matrix, and as its projected Hessian matrix, i.e., .
Sufficient conditions for to be the solution of a nonlinearly-constrained problem are:
(i) is feasible, and ; and
(ii), or, equivalently, ; and
(iii) is positive definite; and
(iv) if corresponds to a constraint of the form .
The sign of is immaterial for equality constraints, which by definition are always active.
Note that condition (ii) implies that the projected gradient of the Lagrangian function must also be zero at , since the application of annihilates the matrix .
2.5Background to Optimization Methods
All the algorithms contained in this chapter generate an iterative sequence that converges to the solution in the limit, except for some special problem categories (i.e., linear and quadratic programming). To terminate computation of the sequence, a convergence test is performed to determine whether the current estimate of the solution is an adequate approximation. The convergence tests are discussed in Section 2.7.
Most of the methods construct a sequence satisfying:
where the vector is termed the direction of search, and is the steplength. The steplength is chosen so that and is computed using one of the techniques for one-dimensional optimization referred to in Section 2.5.1.
2.5.1One-dimensional optimization
The Library contains two special functions for minimizing a function of a single variable. Both functions are based on safeguarded polynomial approximation. One function requires function evaluations only and fits a quadratic polynomial whilst the other requires function and gradient evaluations and fits a cubic polynomial. See Section 4.1 of Gill et al. (1981).
2.5.2Methods for unconstrained optimization
The distinctions between methods arise primarily from the need to use varying levels of information about derivatives of in defining the search direction. We describe three basic approaches to unconstrained problems, which may be extended to other problem categories. Since a full description of the methods would fill several volumes, the discussion here can do little more than allude to the processes involved and direct you to other sources for a full explanation.
(a)Newton-type Methods (Modified Newton Methods)
Newton-type methods use the Hessian matrix , or its finite difference approximation, to define the search direction. The functions in the Library either require a function that computes the elements of the Hessian directly or they approximate them by finite differences.
Newton-type methods are the most powerful methods available for general problems and will find the minimum of a quadratic function in one iteration. See Sections 4.4 and 4.5.1 of Gill et al. (1981).
(b)Quasi-Newton Methods
Quasi-Newton methods approximate the Hessian by a matrix which is modified at each iteration to include information obtained about the curvature of along the current search direction . Although not as robust as Newton-type methods, quasi-Newton methods can be more efficient because the Hessian is not computed directly, or approximated by finite differences. Quasi-Newton methods minimize a quadratic function in iterations, where is the number of variables. See Section 4.5.2 of Gill et al. (1981).
(c)Conjugate-gradient Methods
Unlike Newton-type and quasi-Newton methods, conjugate-gradient methods do not require the storage of an matrix and so are ideally suited to solve large problems.
2.5.3Methods for nonlinear least squares problems
These methods are similar to those for general nonlinear optimization but exploit the special structure of the Hessian matrix to give improved computational efficiency.
Since
the Hessian matrix is of the form
where is the Jacobian matrix of .
In the neighbourhood of the solution, is often small compared to (for example, when represents the goodness-of-fit of a nonlinear model to observed data). In such cases, may be an adequate approximation to , thereby avoiding the need to compute or approximate second derivatives of . See Section 4.7 of Gill et al. (1981).
2.5.4Methods for handling constraints
There are two main approaches for handling constraints in optimization algorithms – the active-set sequential quadratic programming method (or just SQP) and the interior point method (IPM). It is important to understand their very distinct features as both algorithms complement each other. The easiest method of comparison is to look at how the inequality constraints are treated and how the solver approaches the optimal solution (the progress of the KKT optimality measures: optimality, feasibility, complementarity).
Inequality constraints are the hard part of the optimization because of their ‘twofold nature’. If the optimal solution strictly satisfies the inequality, i.e., the optimal point is in the interior of the constraint, the inequality constraint does not influence the result and could be removed from the model. On the other hand, if the inequality is satisfied as an equality (is active at the solution), the constraint must be present and could be treated as an equality from the very beginning. This is expressed by the complementarity in KKT conditions.
Solvers, based on the active-set method, solve at each iteration a quadratic approximation of the original problem; they try to estimate which constraints need to be kept (are active) and which can be ignored. A practical consequence is that the algorithm partly ‘walks along the boundary’ of the feasible region given by the constraints. The iterates are thus feasible early on with regard to all linear constraints (and a local linearization of the nonlinear constraints) which is preserved through the iterations. The complementarity is satisfied by default, and once the active set is determined correctly and optimality is within the tolerance, the solver finishes. The number of iterations might be high but each is relatively cheap. See Chapter 6 of Gill et al. (1981) for further details.
In contrast, an interior point method generates iterations that avoid the boundary defined by the inequality constraints. As the solver progresses the iterates are allowed to get closer and closer to the boundary and converge to the optimal solution which might lie on the boundary. From the practical point of view, IPM typically requires only tens of iterations. Each iteration consists of solving a large linear system of equations taking into account all variables and constraints, so each iteration is fairly expensive. All three optimality measures are reduced simultaneously.
In many cases it is difficult to predict which of the algorithms will behave better on a particular problem, however, some initial guidance can be given in the following table:
IPM advantages
SQP advantages
Can exploit second derivatives and its structure
Efficient on unconstrained or loosely constrained problems
Efficient also for (both convex and nonconvex) quadratic problems (QP)
Better use of multi-core architecture (in multithreaded implementations)
New interface, easier to use
Stay feasible with regard to linear constraints through most of the iterations
Very efficient for highly constrained problems
Better results on pathological problems in our experience
Generally requires less function evaluations (efficient for problems with expensive function evaluations)
Requires first derivatives but can work only with function values
Can capitalize on a good initial point
Allows warm starts (good for a sequence of similar problems)
Infeasibility detection
Unless some of the specific features are required which are offered only by one algorithm, the initial decision should be based on the availability of the derivatives of the problem and the number of constraints (for example, expressed as a ratio between the numbers of variables and the sum of the number of linear and nonlinear constraints). Readiness of exact second derivatives is a clear advantage for IPM so unless the number of constraints is close to the number of variables, IPM will probably work better. Similarly, if a large-scale problem has relatively few constraints (e.g., less than %) IPM might be more successful, especially as the problem gets bigger. On the other hand, if no derivatives are available, either the SQP or a specialized algorithm from the Library (see Derivative-free Optimization, Section 2.2.5) needs to be used. With more and more constraints SQP might be faster. For problems which do not fall in either of the categories, it is not easy to anticipate which solver will work better and some experimentation might be required.
2.5.5Methods for handling multi-objective optimization
Suppose we have objective functions , , all of which we need to minimize at the same time. There are two main approaches to this problem:
(i)Combine the individual objectives into one composite objective. Typically, this might be a weighted sum of the objectives, e.g.,
Here you choose the weights to express the relative importance of the corresponding objective. Ideally each of the should be of comparable size at a solution.
(ii)Order the objectives in order of importance. Suppose are ordered such that is more important than , for . Then in the lexicographical approach to multi-objective optimization a sequence of subproblems are solved. Firstly, solve the problem for objective function and denote by the value of this minimum. If subproblems have been solved with results then subproblem becomes subject to , for plus the other constraints.
Clearly the bounds on might be relaxed at your discretion.
In general, if NAG functions from Chapter E04 are used then only local minima are found. This means that a better solution to an individual objective might be found without worsening the optimal solutions to the other objectives. Ideally you seek a Pareto solution; one in which an improvement in one objective can only be achieved by a worsening of another objective.
To obtain a Pareto solution functions from Chapter E05 might be used or, alternatively, a pragmatic attempt to derive a global minimum might be tried (see e05ucc). In this approach, a variety of different minima are computed for each subproblem by starting from a range of different starting points. The best solution achieved is taken to be the global minimum. The more starting points chosen the greater confidence you might have in the computed global minimum.
2.6Scaling
Scaling (in a broadly defined sense) often has a significant influence on the performance of optimization methods.
Since convergence tolerances and other criteria are necessarily based on an implicit definition of ‘small’ and ‘large’, problems with unusual or unbalanced scaling may cause difficulties for some algorithms.
Although there are currently no user-callable scaling functions in the Library, scaling can be performed automatically in functions which solve sparse LP, QP or NLP problems and in some dense solver functions. Such functions have an optional parameter ‘Scale Option’ which you can set; see individual function documents for details.
The following sections present some general comments on problem scaling.
2.6.1Transformation of variables
One method of scaling is to transform the variables from their original representation, which may reflect the physical nature of the problem, to variables that have certain desirable properties in terms of optimization. It is generally helpful for the following conditions to be satisfied:
(i)the variables are all of similar magnitude in the region of interest;
(ii)a fixed change in any of the variables results in similar changes in . Ideally, a unit change in any variable produces a unit change in ;
(iii)the variables are transformed so as to avoid cancellation error in the evaluation of .
Normally, you should restrict yourself to linear transformations of variables, although occasionally nonlinear transformations are possible. The most common such transformation (and often the most appropriate) is of the form
where is a diagonal matrix with constant coefficients. Our experience suggests that more use should be made of the transformation
where is a constant vector.
Consider, for example, a problem in which the variable represents the position of the peak of a Gaussian curve to be fitted to data for which the extreme values are and ;, therefore, is known to lie in the range –. One possible scaling would be to define a new variable , given by
A better transformation, however, is given by defining as
Frequently, an improvement in the accuracy of evaluation of can result if the variables are scaled before the functions to evaluate are coded. For instance, in the above problem just mentioned of Gaussian curve-fitting, may always occur in terms of the form , where is a constant representing the mean peak position.
2.6.2Scaling the objective function
The objective function has already been mentioned in the discussion of scaling the variables. The solution of a given problem is unaltered if is multiplied by a positive constant, or if a constant value is added to . It is generally preferable for the objective function to be of the order of unity in the region of interest; thus, if in the original formulation is always of the order of (say), then the value of should be multiplied by when evaluating the function within an optimization function. If a constant is added or subtracted in the computation of , usually it should be omitted, i.e., it is better to formulate as rather than as or even . The inclusion of such a constant in the calculation of can result in a loss of significant figures.
2.6.3Scaling the constraints
A ‘well scaled’ set of constraints has two main properties. Firstly, each constraint should be well-conditioned with respect to perturbations of the variables. Secondly, the constraints should be balanced with respect to each other, i.e., all the constraints should have ‘equal weight’ in the solution process.
The solution of a linearly- or nonlinearly-constrained problem is unaltered if the th constraint is multiplied by a positive weight . At the approximation of the solution determined by an active-set solver, any active linear constraints will (in general) be satisfied ‘exactly’ (i.e., to within the tolerance defined by machine precision) if they have been properly scaled. This is in contrast to any active nonlinear constraints, which will not (in general) be satisfied ‘exactly’ but will have ‘small’ values (for example, , , and so on). In general, this discrepancy will be minimized if the constraints are weighted so that a unit change in produces a similar change in each constraint.
A second reason for introducing weights is related to the effect of the size of the constraints on the Lagrange multiplier estimates and, consequently, on the active-set strategy. This means that different sets of weights may cause an algorithm to produce different sequences of iterates. Additional discussion is given in Gill et al. (1981).
2.7Analysis of Computed Results
2.7.1Convergence criteria
The convergence criteria inevitably vary from function to function, since in some cases more information is available to be checked (for example, is the Hessian matrix positive definite?), and different checks need to be made for different problem categories (for example, in constrained minimization it is necessary to verify whether a trial solution is feasible). Nonetheless, the underlying principles of the various criteria are the same; in non-mathematical terms, they are:
(i)is the sequence converging?
(ii)is the sequence converging?
(iii)are the necessary and sufficient conditions for the solution satisfied?
The decision as to whether a sequence is converging is necessarily speculative. The criterion used in the present functions is to assume convergence if the relative change occurring between two successive iterations is less than some prescribed quantity. Criterion (iii) is the most reliable but often the conditions cannot be checked fully because not all the required information may be available.
2.7.2Checking results
Little a priori guidance can be given as to the quality of the solution found by a nonlinear optimization algorithm, since no guarantees can be given that the methods will not fail. Therefore, you should always check the computed solution even if the function reports success. Frequently a ‘solution’ may have been found even when the function does not report a success. The reason for this apparent contradiction is that the function needs to assess the accuracy of the solution. This assessment is not an exact process and consequently may be unduly pessimistic. Any ‘solution’ is in general only an approximation to the exact solution, and it is possible that the accuracy you have specified is too stringent.
Further confirmation can be sought by trying to check whether or not convergence tests are almost satisfied, or whether or not some of the sufficient conditions are nearly satisfied. When it is thought that a function has returned a
value of fail.code other than NE_NOERROR
only because the requirements for ‘success’ were too stringent it may be worth restarting with increased convergence tolerances.
For constrained problems, check whether the solution returned is feasible, or nearly feasible; if not, the solution returned is not an adequate solution.
Confidence in a solution may be increased by restarting the solver with a different initial approximation to the solution. See Section 8.3 of Gill et al. (1981) for further information.
2.7.3Monitoring progress
Many of the functions in the chapter have facilities to allow you to monitor the progress of the minimization process, and you are encouraged to make use of these facilities. Monitoring information can be a great aid in assessing whether or not a satisfactory solution has been obtained, and in indicating difficulties in the minimization problem or in the ability of the function to cope with the problem.
The behaviour of the function, the estimated solution and first derivatives can help in deciding whether a solution is acceptable and what to do in the event of a return with a
fail.code other than NE_NOERROR.
2.7.4Confidence intervals for least squares solutions
When estimates of the parameters in a nonlinear least squares problem have been found, it may be necessary to estimate the variances of the parameters and the fitted function. These can be calculated from the Hessian of the objective at the solution.
In many least squares problems, the Hessian is adequately approximated at the solution by (see Section 2.5.3). The Jacobian, , or a factorization of is returned by all the comprehensive least squares functions and, in addition, e04ycc can be used to estimate variances of the parameters following the use of most of the nonlinear least squares functions, in the case that is an adequate approximation.
Let be the inverse of , and be the sum of squares, both calculated at the solution ; an unbiased estimate of the variance of the th parameter is
and an unbiased estimate of the covariance of and is
If is the true solution then the
confidence interval on is
where is the percentage point of the -distribution with degrees of freedom.
In the majority of problems, the residuals , for , contain the difference between the values of a model function calculated for different values of the independent variable , and the corresponding observed values at these points. The minimization process determines the parameters, or constants , of the fitted function . For any value, , of the independent variable , an unbiased estimate of the variance of is
The comments in this section ONLY apply to functions introduced at Mark 8 and earlier. For details of their optional facilities please refer to their individual documents.
The optimization functions of this chapter provide a range of optional facilities: these offer the possibility of fine control over many of the algorithmic parameters and the means of adjusting the level and nature of the printed results.
Control of these optional facilities is exercised by a structure of type Nag_E04_Opt, the members of the structure being optional input or output arguments to the function. After declaring the structure variable, which is named options in this manual, you must initialize the structure by passing its address in a call to the utility function e04xxc. Selected members of the structure may then be set to your required values and the address of the structure passed to the optimization function. Any member which has not been set by you will indicate to the optimization function that the default value should be used for this argument. A more detailed description of this process is given in Section 3.4.
The optimization process may sometimes terminate before a satisfactory answer has been found, for instance when the limit on the number of iterations has been reached. In such cases you may wish to re-enter the function making use of the information already obtained. Functions e04fcc,e04gbcande04kfc can simply be re-entered but the functions e04kbc,e04mfc,e04ncc,e04nfc,e04nkc,e04ucc,e04uncande04wdc have a structure member which needs to be set appropriately if the function is to make use of information from the previous call. The member is
named start in the functions listed.
3.1Control of Printed Output
Results from the optimization process are printed by default on the stdout (standard output) stream. These include the results after each iteration and the final results at termination of the search process. The amount of detail printed out may be increased or decreased by setting the optional parameter
,
i.e., the structure member . This member is an enum type, Nag_PrintType, and an example value is Nag_Soln which when assigned to will cause the optimization function to print only the final result; all intermediate results printout is suppressed.
If the results printout is not in the desired form then it may be switched off, by setting , or alternatively you can supply your own function to print out or make use of both the intermediate and final results. Such a function would be assigned to the pointer to function member print_fun; the user-defined function would then be called in preference to the NAG print function.
In addition to the results, the values of the arguments to the optimization function are printed out when the function is entered; the Boolean member list may be set to Nag_FALSE if this listing is not required.
Printing may be output to a named file rather than to stdout by providing the name of the file in the options character array member outfile. Error messages will still appear on stderr, if or the fail argument is not supplied (see the Section 7 in the Introduction to the NAG Library CL Interface for details of error handling within the Library).
3.2Memory Management
The options structure contains a number of pointers for the input of data and the output of results. The optimization functions will manage the allocation of memory to these pointers; when all calls to these functions have been completed then a utility function e04xzc can be called by your program to free the NAG allocated memory which is no longer required.
If the calling function is part of a larger program then this utility function allows you to conserve memory by freeing the NAG allocated memory before the options structure goes out of scope. e04xzc can free all NAG allocated memory in a single call, but it may also be used selectively. In this case the memory assigned to certain pointers may be freed leaving the remaining memory still available; pointers to this memory and the results it contains may then be passed to other functions in your program without passing the structure and all its associated memory.
Although the NAG C Library optimization functions will manage all memory allocation and deallocation, it may occasionally be necessary for you to allocate memory to the options structure from within the calling program before entering the optimization function.
An example of this is where you store information in a file from an optimization run and at a later date wish to use that information to solve a similar optimization problem or the same one under slightly changed conditions. The pointer state, for example, would need to be allocated memory by you before the status of the constraints could be assigned from the values in the file. The member
would need to be appropriately set for functions e04mfcande04nfc.
If you assign memory to a pointer within the options structure then the deallocation of this memory must also be performed by you; the utility function e04xzc will only free memory allocated by NAG C Library optimization functions. When your allocated memory is freed using the standard C Library function free() then the pointer should be set to NULL immediately afterwards; this will avoid possible confusion in the NAG memory management system if a NAG function is subsequently entered. In general we recommend the use of NAG_ALLOC, NAG_REALLOC and NAG_FREE for allocating and freeing memory used with NAG functions.
3.3Reading Optional Parameter Values From a File
Optional parameter values may be placed in a file by you and the function e04xyc used to read the file and assign the values to the options structure. This utility function permits optional parameter values to be supplied in any order and altered without recompilation of the program. The values read are also checked before assignment to ensure they are in the correct range for the specified option. Pointers within the options structure cannot be assigned to using e04xyc.
3.4Method of Setting Optional Parameters
The method of using and setting the optional parameters is:
pass the address of the structure to the optimization function.
step 5
call e04xzc to free any memory allocated by the optimization function.
If after step 4, it is wished to re-enter the optimization function, then step 3 can be returned to directly, i.e., step 5 need only be executed when all calls to the optimization function have been made.
At step 3, values can be assigned directly and/or by means of the option file reading function e04xyc. If values are only assigned from the options file then step 2 need not be performed as e04xyc will automatically call e04xxc if the structure has not been initialized.
4Recommendations on Choice and Use of Available Functions
The choice of function depends on several factors: the type of problem (LP, NLP, unconstrained, etc.); whether or not a problem is sparse; the level of derivative information available (function values only, etc.); and other factors. Not all choices are catered for in the current version of the Library.
4.1NAG Optimization Modelling Suite
Mark 26 of the Library introduced the NAG optimization modelling suite, a suite of functions which allows you to define and solve various optimization problems in a uniform manner. The first key feature of the suite is that the definition of the optimization problem and the call to the solver have been separated so it is possible to set up a problem in the same way for different solvers. The second feature is that the problem representation is built up from basic components (building blocks) as defined in Sections 2.2.1 and 2.2.2 (for example, a QP problem is composed of a quadratic objective, simple bounds and linear constraints), therefore, different types of problems reuse the same functions for their common parts.
A connecting element to all functions in the suite is a handle, a pointer to an internal data structure, which is passed among the functions. It holds all information about the problem, the solution and the solver. Each handle should go through four stages in its life: initialization, problem formulation, problem solution and deallocation.
The initialization is performed by e04rac which creates an empty problem with decision variables or alternatively by e04sac which loads the whole model from a file. A call to e04rzc marks the end of the life of the handle as it deallocates all the allocated memory and data within the handle and destroys the handle itself. During this time the handle must only be modified by the provided functions. Working with a handle which has not been properly initialized will result in NE_HANDLE (uniform across the suite) and is potentially very dangerous as it may cause unpredictable behaviour.
After the initialization of an empty problem, the problem formulation should be composed of the basic building blocks. A high degree of freedom is given at this stage. Various types of objective functions and constraints can be defined. Furthermore, editing of the formulation is also supported, which is useful when you need to redefine parts of the problem and resolve. More details on the functions of the suite are as follows.
The objective may be defined as one of the following:
e04rpc – quadratic terms for bilinear matrix inequalities.
There are various ways in which the formulation may be edited. Multiple calls of the functions listed above either extend the formulation (e.g., multiple blocks of linear constraints may be defined) or redefine the component (for instance, a newly defined objective function will overwrite the existing one). In addition, functions are provided to manipulate the formulation further. For example, new variables may be added, a subset of variables within the model may be fixed, existing variables or constraints may be temporarily removed (disabled) from the model and then be brought back (enabled) later. You may modify bounds of an individual constraint, or a coefficient in linear objective or constraint, etc. However, the formulation may not be altered while a solver is running, otherwise NE_PHASE will be returned. The following is a list of editing functions and their functionalities.
e04rcc – specify variable properties, particularly if they are continuous, binary or integer;
e04tcc – disable (temporarily remove) an existing variable or constraint from the model;
e04tbc – enable (bring back) a variable or constraint disabled by e04tcc;
e04tdc – modify bounds of an existing variable or constraint, fix a variable to a certain value;
e04tec – modify the coefficient of a single variable in the linear objective;
e04tjc – modify a single coefficient in a linear constraint;
These functions may be called in an arbitrary order, however, a call to e04rnc must precede a call to e04rpc for the matrix inequalities with bilinear terms and the nonlinear objective or constraints (e04rgcore04rkc) must precede the definition of the second derivatives by e04rlc. Also note that a redefinition of the nonlinear objective function or constraints removes their previously defined Hessians. For further details, please refer to the documentation of the individual functions.
The suite also includes the following service functions:
e04zmc – supply an optional parameter from a character string;
e04zpc – supply one or more optional parameters from a file;
e04znc – get the current value of an optional parameter;
e04rxc – read or write information into the handle via real array, for instance, extract intermediate results during solving;
e04rwc – read or write information into the handle via integer array, for instance, extract the problem size.
When the problem is fully formulated, the handle can be passed to a solver which is compatible with the defined problem. You are free to switch between compatible solvers or resolve after a modification of the formulation, optional parameters and/or starting points. If a solver cannot deal with the given formulation it will return NE_SETUP_ERROR. The NAG optimization modelling suite comprises of the following solvers:
e04ffc,e04fgc – derivative-free nonlinear least squares with box constraints;
e04kfc – first order active-set method for box constrained nonlinear optimization;
e04ggc – bound constrained nonlinear least squares using derivatives;
e04stc – nonlinear programming based on an interior point method;
e04svc – semidefinite programming optionally also with bilinear matrix inequalities.
A diagram of the life cycle of the handle is depicted in Figure 2.
Figure 2
4.2Reverse Communication Functions
Any solver dealing with nonlinear functions needs a way to obtain function values (or derivatives) at each of the trial points during the optimization run. Typically, the objective function and nonlinear constraints (if any) would be written by you as functions to a very rigid format as described in the relevant function document and passed to the solver as callbacks. You call the solver once and the solver calls your callbacks as required. That's the simplest solution and it works in a majority of cases. However, sometimes an alternative in the form of reverse communication functions might be helpful.
Reverse communication functions are called in a loop. The solver stops when it needs to evaluate your functions, the values are computed outside of the solver, and the function is called again with latest values passed in on the argument list. This loop continues until the solver finishes. Such approach is most beneficial when the solver is being called from a computer language which does not fully support procedure arguments in a way that is compatible with the Library. It is also useful if a large amount of data needs to be transmitted into the function. See Section 7 in How to Use the NAG Library for more information about reverse communication functions.
This chapter currently offers the following reverse communication functions: e04fgc,e04jecande04ufc.
4.3Choosing Between Variant Functions for Some Problems
As evidenced by the wide variety of functions available in Chapter E04, it is clear that no single algorithm can solve all optimization problems. It is important to identify the type of problem (see Section 2.2.3) and to try to match the problem to the most suitable function. The decision trees in Section 5 can help you identify the best solver for your problem.
Sometimes in Chapter E04 more than one function is available to solve precisely the same optimization problem. If their differences lay in the underlying method, refer to the sections above. Section 2.5.4 discusses key features of interior point methods (represented by e04stc) and active-set SQP methods (for example, e04ugcore04vhc). Alternatively, there are functions implementing slightly different variants of the same method (such as e04uccande04wdc). Experience shows that in this case although both functions can usually solve the same problem and get similar results, sometimes one function will be faster, sometimes one might find a different local minimum to the other, or, in difficult cases, one function may obtain a solution when the other one fails.
After using one of these functions, if the results obtained are unacceptable, it may be worthwhile trying the other function. In the absence of any other information, in the first instance you are recommended to try using e04ucc, and if that proves unsatisfactory, try using e04wdc. Although the algorithms used are very similar, the two functions each have slightly different optional parameters which may allow the course of the computation to be altered in different ways.
Other pairs of functions which solve the same kind of problem are e04nqc (recommended first choice) or e04nkc, for sparse quadratic or linear programming problems, and e04vhc (recommended) or e04ugc, for sparse nonlinear programming. In these cases the argument lists are not as similar as e04uccore04wdc, but the same considerations apply.
4.4Checking the Derivatives
One of the most common errors in the use of optimization functions is that user-supplied functions do not evaluate the relevant partial derivatives correctly. Because exact gradient information normally enhances efficiency in all areas of optimization, you are encouraged to provide analytical derivatives whenever possible. However, mistakes in the computation of derivatives can result in serious and obscure run-time errors. Consequently, there are mechanisms provided in the Library to perform derivative checks and you are highly encouraged to use them. However, note that the checks are not infallible.
Such checks may be turned on for recent solvers (such as, e04kfc,e04stc,e04uccore04vhc)
directly by optional parameters (see for example, , or ).
For older solvers, there are service functions provided for this task. These functions are inexpensive to use in terms of the number of calls they require to user-supplied functions.
A second type of service function computes a set of finite differences to be used when approximating first derivatives. Such differences are required as input arguments by some functions that use only function evaluations.
e04ycc estimates selected elements of the variance-covariance matrix for the computed regression parameters following the use of a nonlinear least squares function.
e04xac estimates the gradient and Hessian of a function at a point, given a function to calculate function values only, or estimates the Hessian of a function at a point, given a function to calculate function and gradient values.
4.5Function Evaluations at Infeasible Points
All the solvers for constrained problems based on an active-set method will ensure that any evaluations of the objective function occur at points which approximately (up to the given tolerance) satisfy any simple bounds or linear constraints.
There is no attempt to ensure that the current iteration satisfies any nonlinear constraints. If you wish to prevent your objective function being evaluated outside some known region (where it may be undefined or not practically computable), you may try to confine the iteration within this region by imposing suitable simple bounds or linear constraints (but beware as this may create new local minima where these constraints are active).
Note also that some functions allow you to return the argument
()
with a negative value to indicate when the objective function (or nonlinear constraints where appropriate) cannot be evaluated. In case the function cannot recover (e.g., cannot find a different trial point), it forces an immediate clean exit from the function.
Please note that e04nqc,e04vhcande04wdc use the user-supplied function imode instead of .
4.6Related Problems
Apart from the standard types of optimization problem, there are other related problems which can be solved by functions in this or other chapters of the Library.
Several functions in Chapters F04 and F08 solve linear least squares problems, i.e., where .
e02gac solves an overdetermined system of linear equations in the norm, i.e., minimizes , with as above.
e02gcc solves an overdetermined system of linear equations in the norm, i.e., minimizes , with as above.
Chapter E05 contains functions for global minimization.
Section 2.5.5 describes how a multi-objective optimization problem might be addressed using functions from this chapter and from Chapter E05.
5Decision Trees
This section helps you to identify the best solver for your problem. First of all, establish the problem type by referring to Table 1 below and Section 2.2. Then navigate through the particular decision tree to the recommended functions. If more than one function is listed, their order suggests which one to try first. Also see Section 4.3 for further discussion about choosing between variant functions.