The main aim of this chapter is to assist you in finding a function which approximates a set of data points. Typically the data contain random errors, as of experimental measurement, which need to be smoothed out. To seek an approximation to the data, it is first necessary to specify for the approximating function a mathematical form (a polynomial, for example) which contains a number of unspecified coefficients: the appropriate fitting routine then derives for the coefficients the values which provide the best fit of that particular form. The chapter deals mainly with curve and surface fitting (i.e., fitting with functions of one and of two variables) when a polynomial or a cubic spline is used as the fitting function, since these cover the most common needs. However, fitting with other functions and/or more variables can be undertaken by means of general linear or nonlinear routines (some of which are contained in other chapters) depending on whether the coefficients in the function occur linearly or nonlinearly. Cases where a graph rather than a set of data points is given can be treated simply by first reading a suitable set of points from the graph.
The chapter also contains routines for evaluating, differentiating and integrating polynomial and spline curves and surfaces, once the numerical values of their coefficients have been determined.
There is also a routine for computing a Padé approximant of a mathematical function (see Sections 2.6 and 3.8).
2Background to the Problems
2.1Preliminary Considerations
In the curve-fitting problems considered in this chapter, we have a dependent variable and an independent variable , and we are given a set of data points , for . The preliminary matters to be considered in this section will, for simplicity, be discussed in this context of curve-fitting problems. In fact, however, these considerations apply equally well to surface and higher-dimensional problems. Indeed, the discussion presented carries over essentially as it stands if, for these cases, we interpret as a vector of several independent variables and correspondingly each as a vector containing the th data value of each independent variable.
We wish, then, to approximate the set of data points as closely as possible with a specified function, say, which is as smooth as possible: may, for example, be a polynomial. The requirements of smoothness and closeness conflict, however, and a balance has to be struck between them. Most often, the smoothness requirement is met simply by limiting the number of coefficients allowed in the fitting function – for example, by restricting the degree in the case of a polynomial. Given a particular number of coefficients in the function in question, the fitting routines of this chapter determine the values of the coefficients such that the ‘distance’ of the function from the data points is as small as possible. The necessary balance is struck when you compare a selection of such fits having different numbers of coefficients. If the number of coefficients is too low, the approximation to the data will be poor. If the number is too high, the fit will be too close to the data, essentially following the random errors and tending to have unwanted fluctuations between the data points. Between these extremes, there is often a group of fits all similarly close to the data points and then, particularly when least squares polynomials are used, the choice is clear: it is the fit from this group having the smallest number of coefficients.
You are in effect minimizing the smoothness measure (i.e., the number of coefficients) subject to the distance from the data points being acceptably small. Some of the routines, however, do this task themselves. They use a different measure of smoothness (in each case one that is continuous) and minimize it subject to the distance being less than a threshold specified by you. This is a much more automatic process, requiring only some experimentation with the threshold.
2.1.1Fitting criteria: norms
A measure of the above ‘distance’ between the set of data points and the function is needed. The distance from a single data point to the function can simply be taken as
(1)
and is called the residual of the point. (With this definition, the residual is regarded as a function of the coefficients contained in ; however, the term is also used to mean the particular value of which corresponds to the fitted values of the coefficients.) However, we need a measure of distance for the set of data points as a whole. Three different measures are used in the different routines (which measure to select, according to circumstances, is discussed later in this sub-section). With defined in (1), these measures, or norms, are
(2)
(3)
and
(4)
respectively the norm, the norm and the norm.
Minimization of one or other of these norms usually provides the fitting criterion, the minimization being carried out with respect to the coefficients in the mathematical form used for : with respect to the for example if the mathematical form is the power series in (8) below. The fit which results from minimizing (2) is known as the fit, or the fit in the norm: that which results from minimizing (3) is the fit, the well-known least squares fit (minimizing (3) is equivalent to minimizing the square of (3), i.e., the sum of squares of residuals, and it is the latter which is used in practice), and that from minimizing (4) is the , or minimax, fit.
Strictly speaking, implicit in the use of the above norms are the statistical assumptions that the random errors in the are independent of one another and that any errors in the are negligible by comparison. From this point of view, the use of the norm is appropriate when the random errors in the have a Normal distribution, and the norm is appropriate when they have a rectangular distribution, as when fitting a table of values rounded to a fixed number of decimal places. The norm is appropriate when the error distribution has its frequency function proportional to the negative exponential of the modulus of the normalized error – not a common situation.
However, it may be that you are indifferent to these statistical considerations, and simply seek a fit which can be assessed by inspection, perhaps visually from a graph of the results. In this event, the norm is particularly appropriate when the data are thought to contain some ‘wild’ points (since fitting in this norm tends to be unaffected by the presence of a small number of such points), though of course in simple situations you may prefer to identify and reject these points. The norm should be used only when the maximum residual is of particular concern, as may be the case for example when the data values have been obtained by accurate computation, as of a mathematical function. Generally, however, a routine based on least squares should be preferred, as being computationally faster and usually providing more information on which to assess the results. In many problems the three fits will not differ significantly for practical purposes.
Some of the routines based on the norm do not minimize the norm itself but instead minimize some (intuitively acceptable) measure of smoothness subject to the norm being less than a user-specified threshold. These routines fit with cubic or bicubic splines (see (10) and (14) below) and the smoothing measures relate to the size of the discontinuities in their third derivatives. A much more automatic fitting procedure follows from this approach.
2.1.2Weighting of data points
The use of the above norms also assumes that the data values are of equal (absolute) accuracy. Some of the routines enable an allowance to be made to take account of differing accuracies. The allowance takes the form of ‘weights’ applied to the values so that those values known to be more accurate have a greater influence on the fit than others. These weights, to be supplied by you, should be calculated from estimates of the absolute accuracies of the values, these estimates being expressed as standard deviations, probable errors or some other measure which has the same dimensions as . Specifically, for each the corresponding weight should be inversely proportional to the accuracy estimate of . For example, if the percentage accuracy is the same for all , then the absolute accuracy of is proportional to (assuming to be positive, as it usually is in such cases) and so , for , for an arbitrary positive constant . (This definition of weight is stressed because often weight is defined as the square of that used here.) The norms (2), (3) and (4) above are then replaced respectively by
(5)
(6)
and
(7)
Again it is the square of (6) which is used in practice rather than (6) itself.
2.2Curve Fitting
When, as is commonly the case, the mathematical form of the fitting function is immaterial to the problem, polynomials and cubic splines are to be preferred because their simplicity and ease of handling confer substantial benefits. The cubic spline is the more versatile of the two. It consists of a number of cubic polynomial segments joined end to end with continuity in first and second derivatives at the joins. The third derivative at the joins is in general discontinuous. The values of the joins are called knots, or, more precisely, interior knots. Their number determines the number of coefficients in the spline, just as the degree determines the number of coefficients in a polynomial.
2.2.1Representation of polynomials
Two different forms for representing a polynomial are used in different routines. One is the usual power-series form
(8)
The other is the Chebyshev series form
(9)
where is the Chebyshev polynomial of the first kind of degree (see page 9 of Cox and Hayes (1973)), and where the range of has been normalized to run from to . The use of either form leads theoretically to the same fitted polynomial, but in practice results may differ substantially because of the effects of rounding error. The Chebyshev form is to be preferred, since it leads to much better accuracy in general, both in the computation of the coefficients and in the subsequent evaluation of the fitted polynomial at specified points. This form also has other advantages: for example, since the later terms in (9) generally decrease much more rapidly from left to right than do those in (8), the situation is more often encountered where the last terms are negligible and it is obvious that the degree of the polynomial can be reduced (note that on the interval for all , attains the value unity but never exceeds it, so that the coefficient gives directly the maximum value of the term containing it). If the power-series form is used it is most advisable to work with the variable normalized to the range to , carrying out the normalization before entering the relevant routine. This will often substantially improve computational accuracy.
2.2.2Representation of cubic splines
A cubic spline is represented in the form
(10)
where , for , is a normalized cubic B-spline (see Hayes (1974)). This form, also, has advantages of computational speed and accuracy over alternative representations.
2.3Surface Fitting
There are now two independent variables, and we shall denote these by and . The dependent variable, which was denoted by in the curve-fitting case, will now be denoted by . (This is a rather different notation from that indicated for the general-dimensional problem in the first paragraph of Section 2.1, but it has some advantages in presentation.)
Again, in the absence of contrary indications in the particular application being considered, polynomials and splines are the approximating functions most commonly used.
2.3.1Representation of bivariate polynomials
The type of bivariate polynomial currently considered in the chapter can be represented in either of the two forms
(11)
and
(12)
where is the Chebyshev polynomial of the first kind of degree in the parameter (see page 9 of Cox and Hayes (1973)), and correspondingly for . The prime on the two summation signs, following standard convention, indicates that the first term in each sum is halved, as shown for one variable in equation (9). The two forms (11) and (12) are mathematically equivalent, but again the Chebyshev form is to be preferred on numerical grounds, as discussed in Section 2.2.1.
2.3.2Bicubic splines: definition and representation
The bicubic spline is defined over a rectangle in the plane, the sides of being parallel to the and axes. is divided into rectangular panels, again by lines parallel to the axes. Over each panel the bicubic spline is a bicubic polynomial, that is it takes the form
(13)
Each of these polynomials joins the polynomials in adjacent panels with continuity up to the second derivative. The constant values of the dividing lines parallel to the -axis form the set of interior knots for the variable , corresponding precisely to the set of interior knots of a cubic spline. Similarly, the constant values of dividing lines parallel to the -axis form the set of interior knots for the variable . Instead of representing the bicubic spline in terms of the above set of bicubic polynomials, however, it is represented, for the sake of computational speed and accuracy, in the form
(14)
where , for , and , for , are normalized B-splines (see Hayes and Halliday (1974) for further details of bicubic splines and Hayes (1974) for normalized B-splines).
2.4General Linear and Nonlinear Fitting Functions
We have indicated earlier that, unless the data-fitting application under consideration specifically requires some other type of fit, a polynomial or a spline is usually to be preferred. Special routines for these types, in one and in two variables, are provided in this chapter. When the application does specify some other form of fitting, however, it may be treated by a routine which deals with a general linear function, or by one for a general nonlinear function, depending on whether the coefficients occur linearly or nonlinearly.
The general linear fitting function can be written in the form
(15)
where is a vector of one or more independent variables, and the are any given functions of these variables (though they must be linearly independent of one another if there is to be the possibility of a unique solution to the fitting problem). This is not intended to imply that each is necessarily a function of all the variables: we may have, for example, that each is a function of a different single variable, and even that one of the is a constant. All that is required is that a value of each can be computed when a value of each independent variable is given.
When the fitting function is not linear in its coefficients, no more specific representation is available in general than itself. However, we shall find it helpful later on to indicate the fact that contains a number of coefficients (to be determined by the fitting process) by using instead the notation , where denotes the vector of coefficients. An example of a nonlinear fitting function is
(16)
which is in one variable and contains five coefficients. Note that here, as elsewhere in this Chapter Introduction, we use the term ‘coefficients’ to include all the quantities whose values are to be determined by the fitting process, not just those which occur linearly. We may observe that it is only the presence of the coefficients and which makes the form (16) nonlinear. If the values of these two coefficients were known beforehand, (16) would instead be a linear function which, in terms of the general linear form (15), has and
We may note also that polynomials and splines, such as (9) and (14), are themselves linear in their coefficients. Thus if, when fitting with these functions, a suitable special routine is not available (as when more than two independent variables are involved or when fitting in the norm), it is appropriate to use a routine designed for a general linear function.
2.5Constrained Problems
So far, we have considered only fitting processes in which the values of the coefficients in the fitting function are determined by an unconstrained minimization of a particular norm. Some fitting problems, however, require that further restrictions be placed on the determination of the coefficient values. Sometimes these restrictions are contained explicitly in the formulation of the problem in the form of equalities or inequalities which the coefficients, or some function of them, must satisfy. For example, if the fitting function contains a term , it may be required that . Often, however, the equality or inequality constraints relate to the value of the fitting function or its derivatives at specified values of the independent variable(s), but these too can be expressed in terms of the coefficients of the fitting function, and it is appropriate to do this if a general linear or nonlinear routine is being used. For example, if the fitting function is that given in (10), the requirement that the first derivative of the function at be non-negative can be expressed as
(17)
where the prime denotes differentiation with respect to and each derivative is evaluated at . On the other hand, if the requirement had been that the derivative at be exactly zero, the inequality sign in (17) would be replaced by an equality.
Routines which provide a facility for minimizing the appropriate norm subject to such constraints are discussed in Section 3.6.
2.6Padé Approximants
A Padé approximant to a function is a rational function (ratio of two polynomials) whose Maclaurin series expansion is the same as that of up to and including the term in , where is the sum of the degrees of the numerator and denominator of the approximant. Padé approximation can be a useful technique when values of a function are to be obtained from its Maclaurin series but convergence of the series is unacceptably slow or even nonexistent.
3Recommendations on Choice and Use of Available Routines
3.1General
The choice of a routine to treat a particular fitting problem will depend first of all on the fitting function and the norm to be used. Unless there is good reason to the contrary, the fitting function should be a polynomial or a cubic spline (in the appropriate number of variables) and the norm should be the norm (leading to the least squares fit). If some other function is to be used, the choice of routine will depend on whether the function is nonlinear (in which case see Section 3.5.2) or linear in its coefficients (see Section 3.5.1), and, in the latter case, on whether the , or norm is to be used. The latter section is appropriate for polynomials and splines, too, if the or norm is preferred, with one exception: there is a special routine for fitting polynomial curves in the unweighted norm (see Section 3.2.3).
In the case of a polynomial or cubic spline, if there is only one independent variable, you should choose a spline (see Section 3.3) when the curve represented by the data is of complicated form, perhaps with several peaks and troughs. When the curve is of simple form, first try a polynomial (see Section 3.2) of low degree, say up to degree or , and then a spline if the polynomial fails to provide a satisfactory fit. (Of course, if third-derivative discontinuities are unacceptable, a polynomial is the only choice.) If the problem is one of surface fitting, the polynomial routine (see Section 3.4.1) should be tried first if the data arrangement happens to be appropriate, otherwise one of the spline routines (see Section 3.4.3). If the problem has more than two independent variables, it may be treated by the general linear routine in Section 3.5.1, again using a polynomial in the first instance.
Another factor which affects the choice of routine is the presence of constraints, as previously discussed on Section 2.5. Indeed this factor is likely to be overriding at present, because of the limited number of routines which have the necessary facility. Consequently those routines have been grouped together for discussion in Section 3.6.
3.1.1Data considerations
A satisfactory fit cannot be expected by any means if the number and arrangement of the data points do not adequately represent the character of the underlying relationship: sharp changes in behaviour, in particular, such as sharp peaks, should be well covered. Data points should extend over the whole range of interest of the independent variable(s): extrapolation outside the data ranges is most unwise. Then, with polynomials, it is advantageous to have additional points near the ends of the ranges, to counteract the tendency of polynomials to develop fluctuations in these regions. When, with polynomial curves, you can precisely choose the values of the data, the special points defined in Section 3.2.2 should be selected. With polynomial surfaces, each of these same values should, where possible, be combined with each of a corresponding set of values (not necessarily with the same value of ), thus forming a rectangular grid of -values. With splines the choice is less critical as long as the character of the relationship is adequately represented. All fits should be tested graphically before accepting them as satisfactory.
For this purpose it should be noted that it is not sufficient to plot the values of the fitted function only at the data values of the independent variable(s); at the least, its values at a similar number of intermediate points should also be plotted, as unwanted fluctuations may otherwise go undetected. Such fluctuations are the less likely to occur the lower the number of coefficients chosen in the fitting function. No firm guide can be given, but as a rough rule, at least initially, the number of coefficients should not exceed half the number of data points (points with equal or nearly equal values of the independent variable, or both independent variables in surface fitting, counting as a single point for this purpose). However, the situation may be such, particularly with a small number of data points, that a satisfactorily close fit to the data cannot be achieved without unwanted fluctuations occurring. In such cases, it is often possible to improve the situation by a transformation of one or more of the variables, as discussed in the next section: otherwise it will be necessary to provide extra data points. Further advice on curve-fitting is given in Cox and Hayes (1973) and, for polynomials only, in Hayes (1970). Much of the advice applies also to surface fitting; see also the routine documents.
3.1.2Transformation of variables
Before starting the fitting, consideration should be given to the choice of a good form in which to deal with each of the variables: often it will be satisfactory to use the variables as they stand, but sometimes the use of the logarithm, square root, or some other function of a variable will lead to a better-behaved relationship. This question is customarily taken into account in preparing graphs and tables of a relationship and the same considerations apply when curve or surface fitting. The practical context will often give a guide. In general, it is best to avoid having to deal with a relationship whose behaviour in one region is radically different from that in another. A steep rise at the left-hand end of a curve, for example, can often best be treated by curve-fitting in terms of with some suitable value of the constant . A case when such a transformation gave substantial benefit is discussed in page 60 of Hayes (1970). According to the features exhibited in any particular case, transformation of either dependent variable or independent variable(s) or both may be beneficial. When there is a choice it is usually better to transform the independent variable(s): if the dependent variable is transformed, the weights attached to the data points must be adjusted. Thus (denoting the dependent variable by , as in the notation for curves) if the to be fitted have been obtained by a transformation from original data values , with weights , for , we must take
(18)
where the derivative is evaluated at . Strictly, the transformation of and the adjustment of weights are valid only when the data errors in the are small compared with the range spanned by the , but this is usually the case.
3.2Polynomial Curves
3.2.1Least squares polynomials: arbitrary data points
e02adf fits to arbitrary data points, with arbitrary weights, polynomials of all degrees up to a maximum degree , which is a choice. If you are seeking only a low-degree polynomial, up to degree or say, is an appropriate value, providing there are about data points or more. To assist in deciding the degree of polynomial which satisfactorily fits the data, the routine provides the root-mean-square residual for all degrees . In a satisfactory case, these will decrease steadily as increases and then settle down to a fairly constant value, as shown in the example
If the values settle down in this way, it indicates that the closest polynomial approximation justified by the data has been achieved. The degree which first gives the approximately constant value of (degree in the example) is the appropriate degree to select. (If you are prepared to accept a fit higher than sixth degree you should simply find a high enough value of to enable the type of behaviour indicated by the example to be detected: thus you should seek values of for which at least or consecutive values of are approximately the same.) If the degree were allowed to go high enough, would, in most cases, eventually start to decrease again, indicating that the data points are being fitted too closely and that undesirable fluctuations are developing between the points. In some cases, particularly with a small number of data points, this final decrease is not distinguishable from the initial decrease in . In such cases, you may seek an acceptable fit by examining the graphs of several of the polynomials obtained. Failing this, you may (a) seek a transformation of variables which improves the behaviour, (b) try fitting a spline, or (c) provide more data points. If data can be provided simply by drawing an approximating curve by hand and reading points from it, use the points discussed in Section 3.2.2.
3.2.2Least squares polynomials: selected data points
When you are at liberty to choose the values of data points, such as when the points are taken from a graph, it is most advantageous when fitting with polynomials to use the values , for for some value of , a suitable value for which is discussed at the end of this section. Note that these relate to the variable after it has been normalized so that its range of interest is to . e02adf may then be used as in Section 3.2.1 to seek a satisfactory fit. However, if the ordinate values are of equal weight, as would often be the case when they are read from a graph, e02aff is to be preferred, as being simpler to use and faster. This latter algorithm provides the coefficients , for , in the Chebyshev series form of the polynomial of degree which interpolates the data. In a satisfactory case, the later coefficients in this series, after some initial significant ones, will exhibit a random behaviour, some positive and some negative, with a size about that of the errors in the data or less. All these ‘random’ coefficients should be discarded, and the remaining (initial) terms of the series be taken as the approximating polynomial. This truncated polynomial is a least squares fit to the data, though with the point at each end of the range given half the weight of each of the other points. The following example illustrates a case in which degree or perhaps would be chosen for the approximating polynomial.
Basically, the value of used needs to be large enough to exhibit the type of behaviour illustrated in the above example. A value of is suggested as being satisfactory for very many practical problems, the required cosine values for this value of being given on page 11 of Cox and Hayes (1973). If a satisfactory fit is not obtained, a spline fit should be tried, or, if you are prepared to accept a higher degree of polynomial, should be increased: doubling is an advantageous strategy, since the set of values , for , contains all the values of , for , so that the old dataset will then be re-used in the new one. Thus, for example, increasing from to will require only new data points, a smaller number than for any other increase of . If data points are particularly expensive to obtain, a smaller initial value than may be tried, provided you are satisfied that the number is adequate to reflect the character of the underlying relationship. Again, the number should be doubled if a satisfactory fit is not obtained.
3.2.3Minimax space polynomials
e02alf determines the polynomial of given degree which is a minimax space fit to arbitrary data points with equal weights. (If unequal weights are required, the polynomial must be treated as a general linear function and fitted using e02gcf.)
To arrive at a satisfactory degree it will be necessary to try several different degrees and examine the results graphically. Initial guidance can be obtained from the value of the maximum residual: this will vary with the degree of the polynomial in very much the same way as does in least squares fitting, but it is much more expensive to investigate this behaviour in the same detail.
The algorithm uses the power-series form of the polynomial so for numerical accuracy it is advisable to normalize the data range of to .
3.3Cubic Spline Curves
3.3.1Least squares cubic splines
e02baf fits to arbitrary data points, with arbitrary weights, a cubic spline with interior knots specified by you. The choice of these knots so as to give an acceptable fit must largely be a matter of trial and error, though with a little experience a satisfactory choice can often be made after one or two trials. It is usually best to start with a small number of knots (too many will result in unwanted fluctuations in the fit, or even in there being no unique solution) and, examining the fit graphically at each stage, to add a few knots at a time at places where the fit is particularly poor. Moving the existing knots towards these places will also often improve the fit. In regions where the behaviour of the curve underlying the data is changing rapidly, closer knots will be needed than elsewhere. Otherwise, positioning is not usually very critical and equally-spaced knots are often satisfactory. See also the next section, however.
A useful feature of the routine is that it can be used in applications which require the continuity to be less than the normal continuity of the cubic spline. For example, the fit may be required to have a discontinuous slope at some point in the range. This can be achieved by placing three coincident knots at the given point. Similarly a discontinuity in the second derivative at a point can be achieved by placing two knots there. Analogy with these discontinuous cases can provide guidance in more usual cases: for example, just as three coincident knots can produce a discontinuity in slope, so three close knots can produce a rapid change in slope. The closer the knots are, the more rapid can the change be.
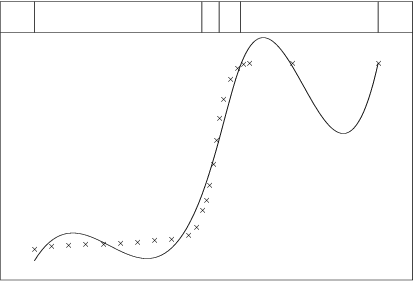
An example set of data is given in Figure 1. It is a rather tricky set, because of the scarcity of data on the right, but it will serve to illustrate some of the above points and to show some of the dangers to be avoided. Three interior knots (indicated by the vertical lines at the top of the diagram) are chosen as a start. We see that the resulting curve is not steep enough in the middle and fluctuates at both ends, severely on the right. The spline is unable to cope with the shape and more knots are needed.
Figure 1
Figure 2
Figure 3
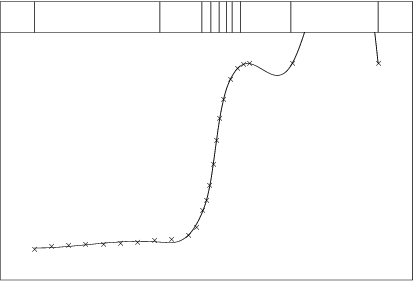
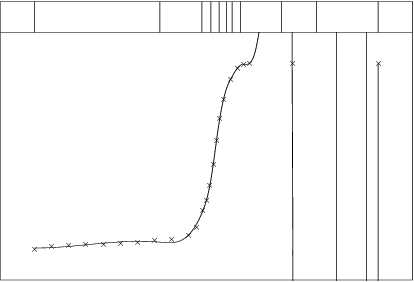
In Figure 2, three knots have been added in the centre, where the data shows a rapid change in behaviour, and one further out at each end, where the fit is poor. The fit is still poor, so a further knot is added in this region and, in Figure 3, disaster ensues in rather spectacular fashion.
The reason is that, at the right-hand end, the fits in Figures 1 and 2 have been interpreted as poor simply because of the fluctuations about the curve underlying the data (or what it is naturally assumed to be). But the fitting process knows only about the data and nothing else about the underlying curve, so it is important to consider only closeness to the data when deciding goodness-of-fit.
Thus, in Figure 1, the curve fits the last two data points quite well compared with the fit elsewhere, so no knot should have been added in this region. In Figure 2, the curve goes exactly through the last two points, so a further knot is certainly not needed here.
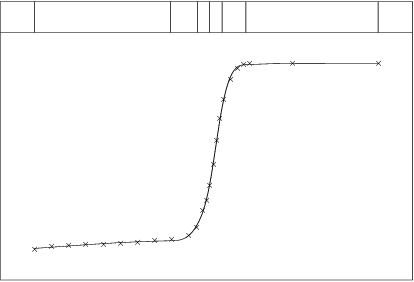
Figure 4 shows what can be achieved without the extra knot on each of the flat regions. Remembering that within each knot interval the spline is a cubic polynomial, there is really no need to have more than one knot interval covering each flat region.
Figure 4
What we have, in fact, in Figures 2 and 3 is a case of too many knots (so too many coefficients in the spline equation) for the number of data points. The warning in the second paragraph of Section 2.1 was that the fit will then be too close to the data, tending to have unwanted fluctuations between the data points. The warning applies locally for splines, in the sense that, in localities where there are plenty of data points, there can be a lot of knots, as long as there are few knots where there are few points, especially near the ends of the interval. In the present example, with so few data points on the right, just the one extra knot in Figure 2 is too many! The signs are clearly present, with the last two points fitted exactly (at least to the graphical accuracy and actually much closer than that) and fluctuations within the last two knot-intervals (see Figure 1, where only the final point is fitted exactly and one of the wobbles spans several data points).
The situation in Figure 3 is different. The fit, if computed exactly, would still pass through the last two data points, with even more violent fluctuations. However, the problem has become so ill-conditioned that all accuracy has been lost. Indeed, if the last interior knot were moved a tiny amount to the right, there would be no unique solution and an error message would have been caused. Near-singularity is, sadly, not picked up by the routine, but can be spotted readily in a graph, as Figure 3. B-spline coefficients becoming large, with alternating signs, is another indication. However, it is better to avoid such situations, firstly by providing, whenever possible, data adequately covering the range of interest, and secondly by placing knots only where there is a reasonable amount of data.
The example here could, in fact, have utilized from the start the observation made in the second paragraph of this section, that three close knots can produce a rapid change in slope. The example has two such rapid changes and so requires two sets of three close knots (in fact, the two sets can be so close that one knot can serve in both sets, so only five knots prove sufficient in Figure 4). It should be noted, however, that the rapid turn occurs within the range spanned by the three knots. This is the reason that the six knots in Figure 2 are not satisfactory as they do not quite span the two turns.
Some more examples to illustrate the choice of knots are given in Cox and Hayes (1973).
3.3.2Automatic fitting with cubic splines
e02bef fits cubic splines to arbitrary data points with arbitrary weights but itself chooses the number and positions of the knots. You have to supply only a threshold for the sum of squares of residuals. The routine first builds up a knot set by a series of trial fits in the norm. Then, with the knot set decided, the final spline is computed to minimize a certain smoothing measure subject to satisfaction of the chosen threshold. Thus it is easier to use than e02baf (see the previous section), requiring only some experimentation with this threshold. It should, therefore, be first choice unless you have a preference for the ordinary least squares fit or, for example, if you wish to experiment with knot positions, trying to keep their number down (e02bef aims only to be reasonably frugal with knots).
3.4Polynomial and Spline Surfaces
3.4.1Least squares polynomials
e02caf fits bivariate polynomials of the form (12), with and specified by you, to data points in a particular, but commonly occurring, arrangement. This is such that, when the data points are plotted in the plane of the independent variables and , they lie on lines parallel to the -axis. Arbitrary weights are allowed. The matter of choosing satisfactory values for and is discussed in Section 9 in e02caf.
3.4.2Least squares bicubic splines
e02daf fits to arbitrary data points, with arbitrary weights, a bicubic spline with its two sets of interior knots specified by you. For choosing these knots, the advice given for cubic splines, in Section 3.3.1 above, applies here too (see also the next section, however). If changes in the behaviour of the surface underlying the data are more marked in the direction of one variable than of the other, more knots will be needed for the former variable than the latter. Note also that, in the surface case, the reduction in continuity caused by coincident knots will extend across the whole spline surface: for example, if three knots associated with the variable are chosen to coincide at a value , the spline surface will have a discontinuous slope across the whole extent of the line .
With some sets of data and some choices of knots, the least squares bicubic spline will not be unique. This will not occur, with a reasonable choice of knots, if the rectangle is well covered with data points: here is defined as the smallest rectangle in the plane, with sides parallel to the axes, which contains all the data points. Where the least squares solution is not unique, the minimal least squares solution is computed, namely that least squares solution which has the smallest value of the sum of squares of the B-spline coefficients (see the end of Section 2.3.2 above). This choice of least squares solution tends to minimize the risk of unwanted fluctuations in the fit. The fit will not be reliable, however, in regions where there are few or no data points.
3.4.3Automatic fitting with bicubic splines
e02ddf fits bicubic splines to arbitrary data points with arbitrary weights but chooses the knot sets itself. You have to supply only a threshold for the sum of squares of residuals. Just like the automatic curve, e02bef (see Section 3.3.2), e02ddf then builds up the knot sets and finally fits a spline minimizing a smoothing measure subject to satisfaction of the threshold. Again, this easier to use routine is normally to be preferred, at least in the first instance.
e02dcf is a very similar routine to e02ddf but deals with data points of equal weight which lie on a rectangular mesh in the plane. This kind of data allows a very much faster computation and so is to be preferred when applicable. Substantial departures from equal weighting can be ignored if you are not concerned with statistical questions, though the quality of the fit will suffer if this is taken too far. In such cases, you should revert to e02ddf.
3.4.4Large data sets
For fitting large sets of equally weighted, arbitrary data points, e02jdf provides a two stage method where local, least squares, polynomial fits are extended to form a surface.
3.5General Linear and Nonlinear Fitting Functions
3.5.1General linear functions
For the general linear function (15), routines are available for fitting in all three norms. The least squares routines (which are to be preferred unless there is good reason to use another norm – see Section 2.1.1) are in Chapters F04 and F08. The routine is e02gcf. Two routines for the norm are provided, e02gafande02gbf. Of these two, the former should be tried in the first instance, since it will be satisfactory in most cases, has a much shorter code and is faster. e02gbf, however, uses a more stable computational algorithm and, therefore, may provide a solution when e02gaf fails to do so. It also provides a facility for imposing linear inequality constraints on the solution (see Section 3.6).
All the above routines are essentially linear algebra routines, and in considering their use we need to view the fitting process in a slightly different way from hitherto. Taking to be the dependent variable and the vector of independent variables, we have, as for equation (1) but with each now a vector,
Substituting for the general linear form (15), we can write this as
(19)
Thus we have a system of linear equations in the coefficients . Usually, in writing these equations, the are omitted and simply taken as implied. The system of equations is then described as an overdetermined system (since we must have if there is to be the possibility of a unique solution to our fitting problem), and the fitting process of computing the to minimize one or other of the norms (2), (3) and (4) can be described, in relation to the system of equations, as solving the overdetermined system in that particular norm. In matrix notation, the system can be written as
(20)
where is the matrix whose element in row and column is , for and . The vectors and respectively contain the coefficients and the data values .
All four
routines, however, use the standard notation of linear algebra, the overdetermined system of equations being denoted by
(21)
(In fact, f04amf can deal with several right-hand sides simultaneously, and thus is concerned with a matrix of right-hand sides, denoted by , instead of the single vector , and correspondingly with a matrix of solutions instead of the single vector .)
The correspondence between this notation and that which we have used for the data-fitting problem (20) is, therefore, given by
(22)
Note that the norms used by these routines are the unweighted norms (2), (3) and (4). If you wish to apply weights to the data points, that is to use the norms (5), (6) or (7), the equivalences (22) should be replaced by
where is a diagonal matrix with as the th diagonal element. Here , for , is the weight of the th data point as defined in Section 2.1.2.
3.5.2Nonlinear functions
Routines for fitting with a nonlinear function are provided in Chapter E04. Consult the E04 Chapter Introduction for the appropriate choice of routine. In particular, e04gnf is the solver from the NAG optimization modelling suite for general nonlinear data-fitting problems with constraints. This supports various forms of fitting, including in the , and norms. Additionally, e04gnf can perform different forms of regularization on the fit parameters and is also able to incorporate linear and nonlinear constraints on these parameters.
3.6Constraints
At present, there are only a limited number of routines which fit subject to constraints. e02gbf allows the imposition of linear inequality constraints (the inequality (17) for example) when fitting with the general linear function in the norm. In addition, Chapter E04 contains a routine, e04gnf, which can be used for fitting with a nonlinear function in the various norms subject to general equality or inequality constraints and subject to regularization of the fitting parameters.
The remaining two constraint routines relate to
fitting with polynomials in the norm.
e02agf deals with polynomial curves and allows precise values of the fitting function and (if required) all its derivatives up to a given order to be prescribed at one or more values of the independent variable. The related surface-fitting e02caf, designed for data on lines as discussed in Section 3.4.1, has a feature which permits precise values of the function and its derivatives to be imposed all along one or more lines parallel to the or axes (see the routine document for the relationship between these normalized variables and your original variables). In this case, however, the prescribed values cannot be supplied directly to the routine: instead, you must provide modified data ordinates and polynomial factors and , as defined on page 95 of Hayes (1970).
3.7Evaluation, Differentiation and Integration
Routines are available to evaluate, differentiate and integrate polynomials in Chebyshev series form and cubic or bicubic splines in B-spline form. These polynomials and splines may have been produced by the various fitting routines or, in the case of polynomials, from prior calls of the differentiation and integration routines themselves.
e02aefande02akf evaluate polynomial curves: the latter has a longer argument list but does not require you to normalize the values of the independent variable and can accept coefficients which are not stored in contiguous locations. e02cbf evaluates polynomial surfaces, e02bbf cubic spline curves, e02defande02dff bicubic spline surfaces, and e02dhf bicubic spline surfaces with derivatives.
Differentiation and integration of polynomial curves are carried out by e02ahfande02ajf respectively. The results are provided in Chebyshev series form and so repeated differentiation and integration are catered for. Values of the derivative or integral can then be computed using the appropriate evaluation routine. Polynomial surfaces can be treated by a sequence of calls of one or other of the same two routines, differentiating or integrating the form (12) piece by piece. For example, if, for some given value of , the coefficients , for , are supplied to e02ahf, we obtain coefficients say, for , which are the coefficients in the derivative with respect to of the polynomial
If this is repeated for all values of , we obtain all the coefficients in the derivative of the surface with respect to , namely
(23)
The derivative of (12), or of (23), with respect to can be obtained in a corresponding manner. In the latter case, for example, for each value of in turn we supply the coefficients , to the routine. Values of the resulting polynomials, such as (23), can subsequently be computed using e02cbf. It is important, however, to note one exception: the process described will not give valid results for differentiating or integrating a surface with respect to if the normalization of was made dependent upon , an option which is available in the fitting routine e02caf.
For splines the differentiation and integration routines provided are of a different nature from those for polynomials. e02bcfande02bff provide values of a cubic spline curve together with its first three derivatives (the rest, of course, are zero) at a given value, or vector of values, of . e02bdf computes the value of the definite integral of a cubic spline over its whole range. Again the routines can be applied to surfaces, this time of the form (14). For example, if, for each value of in turn, the coefficients , for , are supplied to e02bcf with and on each occasion we select from the output the value of the second derivative, say, and if the whole set of are then supplied to the same routine with , the output will contain all the values at of
Equally, if after each of the first calls of e02bcf we had selected the function value (e02bbf would also provide this) instead of the second derivative and we had supplied these values to e02bdf, the result obtained would have been the value of
where and are the end points of the interval over which the spline was defined.
3.8Padé Approximants
Given two non-negative integers and , and the coefficients in the Maclaurin series expansion of a function up to degree , e02raf calculates the Padé approximant of degree in the numerator and degree in the denominator. See Sections 3 and 10 in e02raf for further advice.
e02rbf is provided to compute values of the Padé approximant, once it has been obtained.
4Decision Trees
Note: these Decision Trees are concerned with unconstrained fitting; for constrained fitting, consult Section 3.6.
Tree 1
Do you have reason to choose a type of fitting function other than polynomials or spline?